Recibido: 16/5/2022 / Aceptado: 2/7/2022
doi: https://doi.org/10.26439/interfases2022.n015.5898
Aplicación de machine learning en la gestión de riesgo de crédito financiero: Una revisión sistemática
Juler Anderson Hermitaño Castro
[email protected] / orcid: 0000-0001-6580-880X
Universidad de Lima, Perú
La gestión de riesgos bancarios puede ser dividida en las siguientes tipologías: riesgo crediticio, riesgo de mercado, riesgo operativo y riesgo de liquidez, siendo el primero el tipo de riesgo más importante para el sector financiero. El presente artículo tiene como objetivo mostrar las ventajas y desventajas de la implementación de los algoritmos de machine learning en la gestión de riesgos de crédito y, a partir de esto, mostrar cuál tiene mejor rendimiento, señalando también las desventajas que puedan presentar. Para ello se realizó una revisión sistemática de la literatura con la estrategia de búsqueda PICo y se seleccionaron doce artículos. Los resultados reflejan que el riesgo de crédito es el de mayor relevancia. Además, algunos de los algoritmos de machine learning ya han comenzado a implementarse, sin embargo, algunos presentan desventajas resaltantes como el no poder explicar el funcionamiento del modelo y ser considerados como caja negra. En ese sentido, desfavorece la implementación debido a que los organismos regulatorios exigen que un modelo deba ser explicable, interpretable y transparente. Frente a ello, se ha optado por realizar modelos híbridos con algoritmos que no son sencillos de explicar, como aquellos modelos tradicionales de regresión logística. También, se presenta como alternativa utilizar métodos como SHAPley Additive exPlanations (SHAP) que ayudan a la interpretación de dichos modelos.
PALABRAS CLAVE: machine learning / ML / gestión, riesgo / crédito / algoritmo
Application of Machine Learning in Financial Credit Risk Management:
A systematic review
Banking risk management can be divided into the following typology: credit risk, market risk, operational risk, and liquidity risk, the first being the most important type of risk for the financial sector. This article aims to show the advantages and disadvantages of implementing Machine Learning algorithms in credit risk management. A systematic literature review was carried out with the PICo search strategy, and 12 articles were selected. The results show that credit risk is the most relevant. In addition, some of the Machine Learning algorithms have already begun to be implemented; however, some have significant disadvantages, such as not being able to explain the model's operation and are considered a black box. In this sense, it discourages implementation because regulatory bodies require that a model be explainable, interpretable and transparent. Faced with this, it has been decided to make hybrid models between algorithms that are not easy to explain with traditional ones, such as logistic regression. Also, it is presented as an alternative to using methods such as SHAPley Additive exPlanations (SHAP) that help the interpretation of these models
KEYWORDS: machine learning / ML / management / risk / credit / algorithm
1. INTRODUCCIÓN
El machine learning (ML) es una rama de la inteligencia artificial que puede ser usada en múltiples áreas de investigación académica, desarrollo tecnológico y predicción de datos para empresas (Enterprise.nxt Staff, 2021), ya que su proceso consiste en crear un modelo algorítmico que permite ingresar datos históricos, hacer un entrenamiento según el enfoque que se requiera y, a partir de este, encontrar patrones para predecir alguna información futura. Esto genera que las empresas pongan énfasis en el desarrollo del machine learning, pero es importante que se identifique cuáles son los objetivos que se quieren lograr con su implementación (SAS: Analytics, Artificial Intelligence and Data Management, 2017). Según una publicación en Forbes (2021), el 43 % de empresas ha detectado que la implementación de estos algoritmos ha sido más útil de lo que creían inicialmente y el 50 % ha planeado invertir más en estos modelos el presente año, lo cual empieza a demostrar que ponerlos en funcionamiento es de gran importancia en cualquier sector. Un sector que importa y que genera el movimiento en la economía, es el financiero, el cual lleva implementándolo para mejorar la experiencia al usuario a través de soluciones personalizadas o chatbots como destacó Forbes a la BBVA Corporation (2019). Por otro lado, una actividad que es de gran importancia para cualquier organización o entidad financiera es la gestión de riesgos que puede ser dividida según su taxonomía en: riesgo de seguros y demográfico, riesgo de mercado, riesgo de crédito y riesgo operacional (Mashrur et al., 2020). Al que más enfoque se ha prestado es a los riesgos crediticios para poder mitigar las pérdidas ya sea un banco o una fintech dedicada a préstamos, ya que en el último Risk Dashboard Q1 2021 de la European Banking Authority (EBA) se enfatizó que los bancos seguían siendo vulnerables a los movimientos adversos del riesgo crediticio (KPMG Company, 2021). Por este motivo, se percibe un cambio en el paradigma de no solo optar por los modelos estadísticos tradicionales, sino que cada vez procuren ser más sofisticados como el machine learning para cuantificar y mitigar el riesgo de manera correcta (Mashrur et al., 2020).
Por esta razón, es importante realizar una revisión sistemática de la literatura de investigaciones previas, que permita identificar y centralizar la información de qué algoritmos de machine learning están implementándose dentro de la gestión de riesgos de crédito. Por lo tanto, el objetivo de la presente investigación es mostrar las soluciones que se han propuesto y determinar las ventajas y desventajas que presentan cada uno de estos, ya sea de los modelos tradicionales o algoritmos de machine learning. Asimismo, seguir como modelo una revisión previa, como la encontrada en el artículo de Bhatore, Mohan y Reddy, (2020).
Este documento está estructurado de la siguiente manera: la sección 2 explica los conceptos previos del estudio, la sección 3 describe la metodología de investigación que se empleó para obtener la información, la sección 4 presenta los resultados del estudio, respondiendo a las preguntas planteadas en la sección previa, y, finalmente, la sección 5 muestra la discusión, conclusiones y trabajos futuros.
2. CONCEPTOS Y TÉCNICAS DE MACHINE LEARNING
2.1 Inteligencia artificial y machine learning
El primer concepto se refiere a que un sistema o máquina tiene como objetivo imitar la inteligencia humana al realizar alguna función específica y mejorar conforme se recopilen datos. Asimismo, el machine learning es una parte de la IA que permite lograr ese objetivo deseado, a través de un aprendizaje de los datos y no una programación explícita (IBM, 2018). El machine learning es un subconjunto de la IA, que se puede asociar con una metáfora que consiste en que, “una vez resuelto el problema, es capaz de reconocer la situación problemática y reaccionar usando la estrategia aprendida” (Moreno et al., 1994, p. 6). Los paradigmas que se han planteado para dividir han variado a lo largo del tiempo. Por ejemplo, Moreno et al. señalaban que se podrían dividir entre aprendizaje deductivo, aprendizaje analítico, aprendizaje analógico, aprendizaje inductivo, aprendizaje mediante descubrimiento, entre otros. Sin embargo, como se mencionó, actualmente se ha categorizado de la misma manera por la forma en que aprende el algoritmo: aprendizaje supervisado, aprendizaje no supervisado, aprendizaje semisupervisado, aprendizaje por reforzamiento (Zhang, 2010). La explosión en la investigación que ha tenido el ML, desde los años noventa, se debe a causas como, en primer lugar, “las comunidades de investigación separadas en el aprendizaje automático simbólico, la teoría del aprendizaje computacional, las redes neuronales, las estadísticas y el reconocimiento de patrones se han descubierto entre sí y han comenzado a trabajar juntas” (Dietterich, 1997). En segundo lugar, “las técnicas de aprendizaje automático se están aplicando a nuevos tipos de problemas, incluido el descubrimiento de conocimientos en bases de datos, procesamiento de lenguaje, control de robots y optimización combinatoria, así como a problemas más tradicionales como el reconocimiento de voz, reconocimiento facial, reconocimiento de escritura a mano, médicos, análisis de datos y juego” (Dietterich, 1997).
2.2 Aprendizaje supervisado
Este conjunto de algoritmos utiliza variables etiquetadas para proceder con un entrenamiento. A través de esto, el modelo puede ser capaz de realizar predicciones de ejemplos sin etiquetar. Principalmente, se asocia con problemas de clasificación, regresión y “ranking problem” (Mashrur et al., 2020). Algunos tipos de algoritmos que utilizan el aprendizaje supervisado son regresión lineal, regresión logística, k-nearest neighbor (KNN), support vector machine (SVM), random forest, árboles de decisión y Naive Bayes (Cunningham et al., 2008). Cada uno de estos presentan un grado de dificultad distinto y su utilización depende del contexto en que se necesite.
2.3 Aprendizaje no supervisado
Este conjunto de algoritmos tiene como principal tarea detectar patrones a partir de datos no etiquetados. En el entrenamiento no existen datos etiquetados disponibles y el principal enfoque que se les otorga es resolver problemas de “clustering”, detección de valores atípicos, reducción de dimensionalidad y detección de anomalías (Mashrur et al., 2020). Algunos algoritmos que usan este tipo de aprendizaje son el análisis factorial, principal component analysis (PCA), mezclas de gaussianos, ICA, modelos de Markov ocultos, modelos de espacio de estado (Ghahramani, 2004). Asimismo, K-means, mean shift, K-medoids.
2.4 Aprendizaje profundo (deep learning)
Este tipo de aprendizaje se encuentra dentro del machine learning que tiene un campo de estudio muy amplio, debido a la complejidad de sus modelos y que muchas veces es representado como “caja negra” que extrae representaciones de diferentes capas de características. Se aproxima a una función compuesta no lineal que forma una transformación jerárquica de características en etiquetas (Mashrur et al., 2020).
3. METODOLOGÍA
Para la realización del presente trabajo, se adoptó una revisión sistemática de la literatura (SRL, por sus siglas en inglés). Se optó por realizar una metodología similar a la propuesta por Nina et al. (2021), la cual consta de una planificación para identificar el interés, la población y el contexto actual, el planteamiento de preguntas relevantes para la revisión, una búsqueda de artículos por palabras clave y una construcción de cadenas de búsqueda, y, finalmente, una filtración y selección de artículos. Los pasos detallados son los siguientes:
3.1 Planificación de estudio
En primer lugar, se requirió realizar una planificación del estudio utilizando la técnica PICo:
- Población: Gestión de riesgos de crédito
- Interés: Aplicación de machine learning en el riesgo de crédito
- Contexto: Sector bancario, fintech o financieras, plataformas de préstamos
- Como interés de la presente revisión, se lograron identificar 4 preguntas:
- ¿Qué relevancia presenta el riesgo de crédito dentro de la gestión de riesgos en el sector financiero?
- ¿Cómo el machine learning mejora la predicción del riesgo de crédito financiero frente a métodos tradicionales?
- ¿Qué retos presenta el machine learning frente a los métodos tradicionales?
- ¿Cómo identificar el algoritmo de machine learning más eficaz para la gestión de riesgo de crédito financiero?
3.2 Búsqueda de artículos
En segundo lugar, se utilizó la base de datos de bibliografía indexada Scopus, la cual es frecuente para estudios de revisión sistemática de la literatura. Dado que cuenta con una herramienta que permite realizar búsquedas avanzadas, se optó por identificar palabras claves que permitan realizar una cadena de búsqueda y así realizar un filtrado de artículos. Todas las palabras fueron traducidas al inglés, debido al mayor alcance que este idioma permite.
- Palabras clave: risk management, credit, financial, bank, fintech, lending, machine learning, artificial intelligence
- Cadena de búsqueda: se generaron a partir de conectores lógicos como OR para los sinónimos y AND para la combinación de palabras clave. La cadena que se ingresó fue la siguiente: TITLE-ABS (“RISK MANAGEMENT” AND “CREDIT” AND “FINANCIAL” AND (“BANK” OR “FINTECH” OR “LENDING PLATFORM*”) AND (“MACHINE LEARNING” OR “ML” OR “ARTIFICIAL INTELLIGENCE” OR “AI”)) AND (LIMIT-TO (PUBYEAR, 2022) OR LIMIT-TO (PUBYEAR, 2021) OR LIMIT-TO (PUBYEAR, 2020) OR LIMIT-TO (PUBYEAR, 2019)). Con esta cadena, se obtuvieron 27 resultados.
- Filtrado de artículos: el primer filtrado se realizó en la cadena de búsqueda de acuerdo con los años, en la que se permitieron artículos publicados desde el 2019. Luego, se prosiguió con la lectura de los títulos y abstracts de cada artículo.
3.3 Selección de artículos
En tercer lugar, se realizaron criterios de inclusión y exclusión:
- Criterios de inclusión
- Los artículos científicos informan sobre el uso de machine learning en la gestión de riesgos en el rubro financiero.
- Los artículos científicos fueron revisados por pares.
- Los artículos científicos fueron publicados en revistas de cuartiles Q1, Q2 o Q3.
- Los artículos científicos fueron publicados en entre los años 2019 y 2022.
- Criterios de exclusión
- Los artículos científicos no informan sobre el uso del machine learning en la gestión de riesgos financieros.
- Los artículos científicos no fueron revisados por pares.
- Los artículos científicos son de publicaciones anteriores al 2019.
Luego de aplicar estos criterios, se analizaron 12 artículos y 1 capítulo de libro.
Tabla 1
Artículos revisados para el análisis de las preguntas
|
Item |
Año |
Nombre |
Autores |
Journal |
|
1 |
2022 |
Machine learning for credit scoring: Improving logistic regression with non-linear decision-tree effects |
Dumitrescu, E., Hué, S., Hurlin, C., & Tokpavi, S. |
European Journal of Operational Research |
|
2 |
2022 |
Financial risk management and explainable, trustworthy, responsible AI |
Fritz-Morgenthal, S., Hein, B. & Papenbrock, J. |
Frontiers in Artificial Intelligence |
|
3 |
2021 |
Prospects of artificial intelligence and machine learning application in banking risk management |
Milojević, N., & Redzepagic, S |
Journal of Central Banking Theory and Practice |
|
4 |
2021 |
Explainable machine learning in credit risk management |
Bussmann, N., Giudici, P., Marinelli, D., & Papenbrock, J. |
Computational Economics |
|
5 |
2021 |
Classical machine learning methods in economics research: Macro and micro level examples |
Babenko, V., Panchyshyn, A., Zomchak, L., Nehrey, M., Artym-Drohomyretska, Z., & Lahotskyi, T. |
WSEAS Transactions on Business and Economics |
|
6 |
2021 |
Research on Credit Risk Control of Commercial Banks Based on Data Mining Technology |
Cui, H |
IEEE CBFD Conference |
|
7 |
2021 |
Comparative Analysis of Machine Learning Models on Loan Risk Analysis |
Srinivasa Rao, Sekhar, & Bhattacharyya |
Advances in Intelligent Systems and Computing |
|
8 |
2020 |
Machine learning for financial risk management: A survey |
Mashrur, A., Luo, W., Zaidi, N., & Robles-Kelly, A. |
IEEE Access |
|
9 |
2020 |
Explainable AI in fintech risk management |
Bussmann, N., Giudici, P., Marinelli, D., & Papenbrock, J. |
Frontiers in Artificial Intelligence |
|
10 |
2020 |
Risk attribution and interconnectedness in the EU via CDS data |
Giacometti, Torri, Farina, & De Giuli |
Computational Management Science |
|
11 |
2020 |
DGHNL: A new deep genetic hierarchical network of learners for prediction of credit scoring |
Plawiak, Abdar, Plawiak, Makarenkov, & Acharya |
Information Sciences |
|
12 |
2020 |
Estimation procedures of using five alternative machine learning methods for predicting credit card default |
Teng, H-W. & Lee, M. |
[Libro] Handbook of financial econometrics, mathematics, statistics, and machine learning |
|
13 |
2019 |
Machine learning in banking risk management: A literature review |
Leo, M., Sharma, S., & Maddulety, K. |
Risks |
4. RESULTADOS
La presente sección responde a cada una de las preguntas planteadas previamente en la primera sección de la metodología.
4.1 ¿Qué relevancia presenta el riesgo de crédito dentro de la gestión de riesgos en el sector financiero?
El riesgo crediticio es el mayor riesgo al que se puede enfrentar un banco, ya que evita pérdidas y maximiza ganancias, lo cual es vital para cualquier empresa (Mashrur et al., 2020). Asimismo, es importante determinar el riesgo de crédito desde una perspectiva macroprudencial considerando al sector bancario como un sistema complejo y no como instituciones individuales (Giacometti et al., 2020).
La gestión de riesgos financieros (FRM) puede ser dividida en gestión de riesgos demográficos y de seguros, gestión de riesgo crediticio, gestión de riesgo de mercado, y gestión de riesgo operacional (Mashrur et al., 2020). Sin embargo, el desarrollo e implementación de machine learning se ha priorizado en el segundo tipo de gestión mencionado, debido a que es el más importante. También, se percibe a través de la mención de su importancia en 7 de los 12 papers consultados en la revisión, tales como los ítems 3, 6, 7, 8, 10, 11 y 13 de la tabla 1. Tal como se señala Cui (2021) y Srinivasa et al. (2021) la gestión del riesgo de crédito en los bancos es crucial para evitar el riesgo de perder dinero debido a los malos préstamos.
Como se sabe, el riesgo de crédito es la incertidumbre que involucra la capacidad de cumplir cierta obligación monetaria de algún prestatario. El prestatario puede ser una persona u organización (Mashrur et al., 2020). Por lo tanto, es necesario poder realizar un análisis que permita conocer al prestador, el nivel de pérdidas que puede llegar a tener en caso ocurriera algún incumplimiento de los acreditados. Este puede ser determinado con un factor importante como es la calificación crediticia, ya que es crucial para el análisis del préstamo, pues permite identificar a quiénes se debería otorgar el crédito (Plawiak et al., 2020). Además, otro objetivo de esta medición es la estimación de determinar las pérdidas esperadas y no esperadas (Elizondo, 2003). Como se detalla en el libro Medición integral del riesgo de crédito, “representa el monto de capital que podría perder una institución, como resultado de la exposición al riesgo de crédito” (Elizondo, 2003, p. 50). De acuerdo a los Acuerdos de Basilea III, las técnicas para la gestión del riesgo de crédito pueden ser tipo estandarizadas o basadas en calificaciones internas. Estas últimas se calculan mediante la multiplicación de probabilidad de incumplimiento (PD), pérdida en caso de incumplimiento (LGD) y la exposición al incumplimiento (EAD) (Superintendencia de Banca, Seguros y AFP, s. f.). Entonces, se permite que cada entidad pueda desarrollar sus propios modelos de riesgo con los parámetros de riesgo clave lo cual puede resultar en una pérdida esperada (EL) con la multiplicación de estos tres (Bank for International Settlements, 2005). Asimismo, si no se cuenta con una buena práctica de la gestión de riesgos de créditos, cualquier entidad corre riesgo, ya que es una de las principales oportunidades para mejorar el desempeño general de la organización y asegurar una ventaja competitiva frente a los demás (SAS: Analytics, Artificial Intelligence and Data Management, 2015).
4.2 ¿Cómo el machine learning mejora la predicción del riesgo de crédito frente a métodos tradicionales?
Los algoritmos clasificadores de machine learning funcionan de forma significativamente más precisa que los métodos estadísticos estándar en la calificación crediticia, lo cual ofrece más valor a la gestión de riesgos.
Dentro de la gestión de riesgo crediticio, inicialmente las decisiones de admisión de créditos se tomaban con evaluaciones subjetivas, dependiendo de la experiencia. Luego fue se reemplazó por métodos estadísticos tradicionales, de los cuales el más usado ha sido el análisis discriminante lineal (LDA) o también regresión logística para determinar la probabilidad de incumplimiento (Leo et al., 2020). Sin embargo, en los últimos años se ha implementado dos tipos de métodos de aprendizaje automático: supervisado y no supervisado. De los primeros, se utilizan los clasificadores únicos, de los cuales se señala que muchos estudios han demostrado que hay dos que se pueden utilizar eficazmente para predecir la quiebra o calificar el crédito, los cuales son las support vector machine (SVM) y las redes neuronales. De los segundos, el método que se usa es de agrupación y se puede utilizar para identificar el riesgo de quiebra o incumplimiento crediticio, además ayuda a identificar grupos de solicitantes de préstamos y ofrece un modelo de puntuación dinámico basado en conglomerados, el cual mejora la precisión de puntuación (Mashrur et al., 2020). Además, Dumitrescu et al. (2021) agregan que los métodos de árboles de decisión y random forest proporcionan un mejor rendimiento de clasificación que los modelos de regresión logística estándar. Como mencionan Leo et al., (2020), en el enfoque de machine learning, el algoritmo support vector machine, al igual que otros, tiene éxito al clasificar a los clientes que incumplen e incluso son competitivos en el descubrimiento de características significantes para determinar el riesgo de incumplimiento. En adición a esto, se pueden implementar los algoritmos de ML a los métodos cotidianos, tal como lo realizaron Dumitrescu et al. (2021), en el que combinan la regresión logística tradicional con el algoritmo de árboles de decisión. Esto último logra transmitir que no se opte solo por algún método, sino que los modelos tradicionales pueden trabajar correctamente con el ML.
4.3 ¿Qué retos presenta el machine learning frente a los métodos tradicionales?
Actualmente, existen inconvenientes con la adopción de estos nuevos modelos, ya que, al inicio, a algunos de estos se les solía etiquetar como “caja negra”, término que se refería a que era difícil poder explicar el funcionamiento del modelo y cómo lograr el resultado que se podía obtener. En ese sentido, las entidades regulatorias no permiten la implementación de este tipo de modelos, ya que se requiere explicabilidad, interpretabilidad y transparencia de los modelos (Fritz-Morgenthal et al., 2022).
El término “caja negra” se le atribuye a la tecnología, ya que su auge ha sido expo-nencial y cada vez más compleja. Especialmente, se les etiqueta este término a los algoritmos de aprendizaje profundo (deep learning), ya que resulta el más complejo de entender (Castelvecchi, 2016), pero ciertos algoritmos de machine learning también pueden contener esta característica. Además, Mashrur et al. (2020) contribuyen a esta afirmación sobre que estos algoritmos poseen una naturaleza estocástica y no se puede lograr una completa explicación de modelo en algunos casos, lo cual representa un problema, ya que en el dominio financiero se necesita que las decisiones sean tomadas con fines éticos y regulatorios y muchas veces no es compatible con los requisitos regulatorios financieros (Dumitrescu et al., 2021). Por ejemplo, en el caso de Perú, se debe informar a la SBS la explicabilidad de algún modelo implementado. Bussmann et al. (2021) refuerzan indicando que la inteligencia artificial no es adecuada en servicios financieros regulados, porque no se cumple que sea “explicable” e “interpretable”. El primer término corresponde a que se puedan responder preguntas sobre el funcionamiento de un modelo según el grupo de interés al que se dirigen; en cuanto al segundo término, corresponde a que la parte interesada pueda comprender los impulsores de la decisión tomada por el modelo. Además, el mismo paper señala que, si bien la IA mejora la conveniencia y accesibilidad de los servicios financieros, también se desencadenan nuevos riesgos. Los modelos de aprendizaje estadísticos “simples” pueden proporcionar alta interpretabilidad, pero limitada precisión predictiva. A diferencia de estos, los modelos de aprendizaje automático “complejos”, como las redes neuronales y los modelos de árbol, son totalmente opuestos: alta precisión predictiva, pero interpretación limitada. La misma conclusión pudieron obtener los mismos autores en la investigación realizada para fintechs (Bussmann et al., 2020). Además, otro enfoque para lograr la explicabilidad necesaria de los modelos se está optando por metodologías como SHAP (SHAPley Additive exPlanations), la cual es una herramienta de visualización usada para este objetivo. Si bien es entendida por científicos de datos o desarrolladores o validadores del modelo, con capacitación se puede lograr que otras personas relevantes y participantes del negocio, como auditores, organismos de supervisión o clientes, puedan comprender y mencionar qué variables son las más importantes para el resultado que se obtenga, y mostrar que el resultado no es de causalidad (Fritz-Morgenthal et al., 2022).
Por otro lado, se conoce que para el entrenamiento del modelo se requieren datos previos y etapas de selección de variables, análisis descriptivos, estimación de parámetros y selección del modelo adecuado (Babenko et al., 2021), lo cual es realizado por algún analista y esto podría caer en sesgos al seleccionar los datos (Leo et al., 2020), asimismo puede haber una falta de equidad, ya que existen estos sesgos externos que pueden instigar a los modelos de calificación crediticia (Mashrur et al., 2020). Por ejemplo, en esta misma investigación de Babenko et al., se consideraron a las variables independientes edad, sexo, estado civil, número de dependientes, ingreso mensual, residencia, tipo de apartamento, garantes, número de préstamos devueltos, y otros datos más del prestatario; la variable dependiente o “target” fue “creditability”, pero esto no indica que sean las variables que siempre se deban considerar en cualquier modelo, ya que es muy dependiente de los datos con los que se pueda contar. Adicionalmente, se requiere de disponibilidad de personal capacitado, ética en la recopilación, protección y transparencia de los datos.
4.4 ¿Cómo identificar el algoritmo de machine learning más eficaz para la gestión de riesgo de crédito financiero?
Son diversos algoritmos de machine learning e identificar uno de estos como el más adecuado es una tarea complicada; sin embargo, se realizan diversas acciones y métricas para poder determinar si el modelo es adecuado. Para esta función, se toma en cuenta la matriz de confusión y, a partir de esta, poder determinar la sensibilidad y especifidad del modelo. Asimismo, se analiza la curva ROC, o AUC en inglés, para calcular el área bajo su curva.
El término “sensibilidad” se refiere a la proporción de predicción correcta de que cumplen con el caso (verdaderos positivos) sobre el número total de personas que cumplen el caso. Con respecto a la “especifidad”, se refiere a la proporción de predicción correcta de que no cumplen con el caso (verdaderos negativos) sobre el número total de personas que no cumplen el caso (Visa et al., 2011). Por otro lado, también se puede utilizar una curva ROC para obtener una determinación más rigurosa. El proceso para hacerlo es el siguiente: se deben tabular las sensibilidades y especifidades para diferentes valores de una medida de prueba continua. “Luego, la curva ROC gráfica se produce trazando la sensibilidad (tasa de verdaderos positivos) en el eje Y, contra la especificidad 1 (tasa de falsos positivos) en el eje X para los diversos valores tabulados” (Hui Hoo et al., 2017). El área bajo la curva ROC (AUC) es la capacidad de una prueba para discriminar si una condición específica está presente o no. Si el AUC es de 0,5, representa una prueba sin capacidad de discriminación. Si el AUC resulta de 1,0, representa una prueba con discriminación perfecta (Hui Hoo et al., 2017). Por ejemplo, en el artículo científico de Babenko et al. (2021) emplearon un modelo clásico de regresión lineal cuyas variables independientes fueron edad, sexo, estado civil, número de dependientes, ingreso mensual, residencia, tipo de apartamento, garantes, número de préstamos devueltos, y otros datos más del prestatario; la variable dependiente o “target” fue “creditability”. La sensibilidad entregada del modelo fue de 91 % y la especificidad del 80 %, lo cual significa que el 91 % de prestatarios confiables recibirán el préstamo (verdaderos positivos) y el 9 % restante son prestatarios no confiables que recibirán el préstamo (falsos positivos). Para evaluar la calidad del modelo se usó una matriz de clasificación y la curva ROC, la cual muestra la dependencia del número de resultados positivos correctamente clasificados del número de consecuencias negativas incorrectamente clasificadas. El área bajo la curva resultó 0,9, lo cual muestra alto poder predictivo y fiabilidad del modelo (Babenko et al., 2021).
Figura 1
Curva ROC para el modelo de puntuación de regresión logística
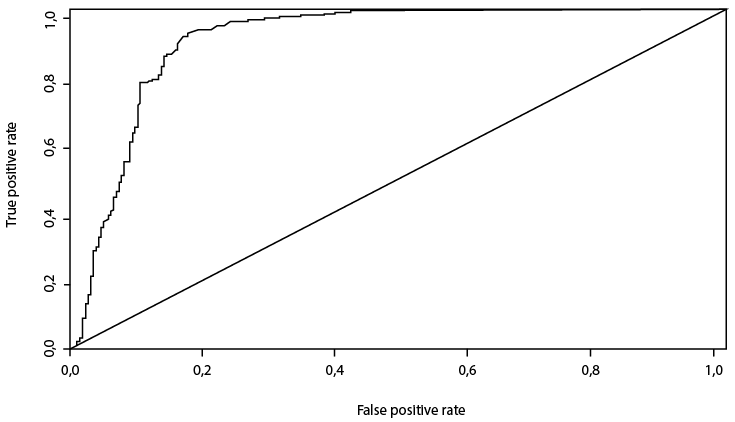
Nota. Área bajo la curva de la curva ROC para el modelo generado de regresión logística, cuyo resultado fue 0,9. De “Classical machine learning methods in economics research: Macro and micro level examples”, por V. Babenko, A. Panchyshyn, L. Zomchak, M. Nehrey, Z. Artym-Drohomyretska, y T. Lahotskyi, 2021, WSEAS Transactions on Business and Economics, 18, p. 213 ( https://doi.org/10.37394/23207.2021.18.22).
Sin embargo, determinar el algoritmo óptimo es muy variable, más incluso considerando los desafíos que se mostraron en la pregunta anterior, ya que no solo depende del nivel de sensibilidad, especificidad o el área bajo la curva ROC. Algunos de estos modelos de ML ya están interactuando con los tradicionales. Por ejemplo, en el caso de Dumitrescu et al. (2021), implementaron un algoritmo basado en un método de calificación crediticia que sea interpretable y de alto rendimiento al cual denominan regresión de árbol logístico penalizado (PLRT), donde concluyen que, mediante una simulación de Montecarlo, el modelo PLRT predice de manera significativamente más precisa que la regresión logística, regresión logística no lineal, regresión logística no lineal con lazo adaptativo y support vector machine se comparan a un nivel similar con random forest.
Otro ejemplo, es el artículo “Explainable machine learning in credit risk management”, en el que se propone un modelo de inteligencia artificial basado en redes de correlación a los valores de Shapley que puede ser utilizado en la gestión de riesgo crediticio y, en particular, midiendo riesgos cuando ocurre que el crédito es tomado empleando plataformas de préstamos entre pares. Para este objetivo, se tomó una muestra de 15 mil pequeñas y medianas empresas (riesgosos y no riesgosos) que solicitaron crédito, los cuales van a poder agruparse de acuerdo con sus características financieras similares y así otorgar puntajes crediticios y predecir comportamientos futuros. La principal contribución es mejorar los valores de Shapley partiendo de la interpretación del resultado predictivo de un modelo de aprendizaje automático mediante modelos de red de correlación.
De acuerdo con los artículos científicos mencionados anteriormente, se puede determinar que los algoritmos de machine learning basados en modelos estadísticos “simples” como la regresión logística son mejores que los métodos tradicionales, como el análisis de discriminante lineal, que se aplicaban en el pasado; asimismo, los algoritmos más “complejos” actuales representan superioridad en cuanto a mejor predicción de las variables a predecir: riesgoso o no riesgoso. Sin embargo, estos tipos de modelos son catalogados como una “caja negra”; es decir, no se sabe con exactitud cómo ocurre el proceso de selección a través de clasificación o “clusterización”. Debido a estos problemas de explicabilidad e interpretabilidad, se ha optado por el desarrollo de algoritmos que representan un híbrido para que se puedan cumplir (los estándares de regulación a nivel financiero).
A continuación, se muestran los posibles eventos que conllevan la implementación de los diversos algoritmos tradicionales y de machine learning, mencionados a través de la revisión sistemática de literatura, y los riesgos que pueden representar:
Tabla 2
Ventajas y desventajadas de cada algoritmo
|
Técnica |
Ventaja |
Desventaja |
|
Estadística tradicional (cartera atrasa y refinanciada, morosidad según tipo de crédito, cobertura de atrasos, cobertura de morosidad) |
La capacitación del personal es menos especializada en algoritmos y se basa en conocimientos estadísticos. |
Puede haber subjetividad o sesgos en la recopilación de datos. |
|
Análisis de discriminante lineal (LDA) |
Se considera como método tradicional a pesar de ser un algoritmo de clasificación, ya que lleva tiempo utilizándose y no presenta mucha incertidumbre (Mashrur et al., 2020). |
La eficiencia y eficacia del modelo está limitada y se puede presentar subjetividad al momento de seleccionar los datos históricos (Mashrur et al., 2020). |
|
Regresión logística |
Es el algoritmo que suele ser más empleado actualmente, ya que se considera como transparente y no identificado como “caja negra”, debido a que no tiene la característica de alta complejidad (Leo et al., 2020). |
Queda superada por algoritmos más complejos como SMV, Naive Bayes o random forest (Bussmann et al., 2020, Explainable AI in fintech risk management). |
|
Support vector machine |
Tiene éxito en la clasificación e incluso son competitivos en el descubrimiento de características significantes para determinar el riesgo de incumplimiento (Leo et al., 2020). |
Es considerado de naturaleza estocástica, ya que existe incertidumbre en el modelo (Mashrur et al., 2020). Su funcionamiento empeora a medida que hay un aumento de datos de ingreso (Teng & Lee, 2020). |
|
Árboles de decisión (decision tree) |
Posee una precisión (accuracy en inglés) regular, mejor que los métodos tradicionales o los mencionados anteriormente, y logra tener una explicabilidad ante organismos reguladores (Dumitrescu et al., 2021). Obtuvo mayor precisión y funcionó más rápido frente a SVM y KNN (Teng & Lee, 2020). |
Solo se ha demostrado que es superior a los anteriores considerando la métrica de accuracy (Teng & Lee, 2020). |
|
Random forest |
Posee mejor rendimiento que la regresión logística estándar, ya que se adapta mejor a efectos de umbral univariados y multivariados no observados (Dumitrescu et al., 2021). Se beneficia de la partición recursiva subyacente de los árboles de decisión (Dumitrescu et al., 2021). |
Posee problemas de explicabilidad del modelo y requiere de un conjunto de datos que no sea pequeño e incluso puede caer en un sobreajuste del modelo (Mashrur et al., 2020). |
|
Regresión de árbol logístico penalizado (PLRT) |
Es más preciso que regresión logística, support vector machine y a un nivel similar que random forest (Dumitrescu et al., 2021). Es interpretable y de alto rendimiento, lo cual podría cumplir los requisitos reguladores financieros (Dumitrescu et al., 2021). |
Requiere un alto grado de especialización para la utilización del algoritmo. Además, no es estándar, sino que es una propuesta de los autores, por lo cual se tendría que analizar en cada caso particular (Dumitrescu et al., 2021). |
|
Redes neuronales |
Tiene la capacidad propia de encontrar patrones y no se necesita de etiquetas previas (Mashrur et al., 2020). |
El modelo puede sufrir dificultades de generalización y con ello producir modelos donde exista sobreajuste. (Zhang, 2020, p. 617). Representa el nivel más alto para considerarse como “caja negra”, además de un nivel de especialización mucho mayor que en los algoritmos anteriores, ya que la dificultad es alta (Mashrur et al., 2020). |
5. CONCLUSIONES
Los algoritmos de machine learning se llevan utilizando un periodo de tiempo considerable, por lo cual es notoria la evolución que han tenido, asimismo ha habido un aumento importante en la gestión de riesgos de cualquier entidad que se dedique al rubro financiero, pero ha existido un mayor énfasis en la gestión de riesgo de crédito, debido a que representa el mayor riesgo, ya que evita pérdidas y ganancias en las organizaciones. Asimismo, se ha podido determinar que el machine learning representa ventajas frente a los métodos tradicionales, ya que obtienen mejor éxito para clasificar a los potenciales clientes. Sin embargo, es importante señalar que algunos de estos modelos no son fáciles de explicar en cuanto a su funcionamiento, por lo que se les etiqueta como “caja negra” y eso representa una desventaja para su implementación, ya que primero debe lograrse un visado por parte del sistema regulatorio financiero, además de necesitar personal especializado, ética en la recopilación, protección, transparencia y tratamiento de datos; sin embargo, estos problemas también podrían ocurrir en el cálculo tradicional. A pesar de esto, se han comenzado a desarrollar algoritmos “híbridos” entre modelos complejos y regresión logística para que se puedan cumplir los estándares regulatorios que se requieren en el rubro financiero, por lo que se puede observar una tendencia positiva en la adopción de modelos. El que obtuvo mejor rendimiento en casos aislados fue la propuesta híbrida de regresión de árbol logístico penalizado, pero, como se detalla en el cuadro, se necesita capacitación de personal que maneje algoritmos de machine learning, ya que es una propuesta nueva; cabe mencionar que esta superioridad fue mostrada con comparaciones que se realizaron para casos aislados, por lo que se recomienda tomarlo como una referencia teórica. Asimismo, es importante que estos modelos sean entrenados no solo con un conjunto de datos, sino que se deben usar múltiples veces para ilustrar la solidez frente a cualquier caso que se presente. Finalmente, se mostraron las métricas y métodos para poder determinar si un algoritmo es óptimo y se recomienda utilizar estas herramientas como corroboración. De igual manera, es importante para la organización o entidad poder analizar el mejor algoritmo a implementar de acuerdo con sus características propias, los datos con los que se cuente y en nivel de explicabilidad que se pueda brindar.
REFERENCIAS
Babenko, V., Panchyshyn, A., Zomchak, L., Nehrey, M., Artym-Drohomyretska, Z., & Lahotskyi, T. (2021). Classical machine learning methods in economics research: Macro and micro level examples. WSEAS Transactions on Business and Economics, 18, 209-2017. https://doi.org/10.37394/23207.2021.18.22
Bank for International Settlements. (2005). An explanatory note on the Basel II IRB Risk Weight Functions. Basel Committee on Banking Supervision. https://www.bis.org/bcbs/irbriskweight.htm
BBVA Corporation. (2019, 6 de febrero). Forbes destaca los usos que BBVA hace de la inteligencia artificial. BBVA. https://www.bbva.com/es/forbes-destaca-los
-usos-que-bbva-hace-de-la-inteligencia-artificial/
Bhatore, S., Mohan, L., & Reddy, R. (2020). Machine learning techniques for credit risk evaluation: a systematic literature review. Journal of Banking and Financial Technology, 4, 111-138. https://doi.org/10.1007/s42786-020-00020-3
Bussmann, N., Giudici, P., Marinelli, D., & Papenbrock, J. (2020). Explainable AI in fintech risk management. Frontiers in Artificial Intelligence, 1-5. https://doi.org/10.3389/frai.2020.00026
Bussmann, N., Giudici, P., Marinelli, D., & Papenbrock, J. (2021). Explainable machine learning in credit risk management. Computational Economics, 57(1), 203-216. https://doi.org/10.1007/s10614-020-10042-0
Castelvecchi, D. (2016). Can we open the black box of AI? Nature, 538, 20-23. https://doi.org/10.1038/538020a
Columbus, L. (2021, 17 de enero). 76% of enterprises prioritize AI & machine learning in 2021 IT budgets. Forbes. https://www.forbes.com/sites/louis
columbus/2021/01/17/76-of-enterprises-prioritize-ai--machine-learning-in-2021-it-budgets/?sh=6f9c20c618a3
Cui, H. (2021). Research on Credit Risk Control of Commercial Banks Based on Data Mining Technology. 2021 International Conference on Computer, Blockchain and Financial Development, (pp. 383-386). https://doi.org/10.1109/CBFD52659.2021.00083
Cunningham, P., Cord, M., & Delany, S. J. (2008). Supervised learning. En M. Cord y P. Cunningham (Eds.), Machine learning techniques for multimedia. Cognitive technologies (pp. 21-49). https://doi.org/10.1007/978-3-540-75171-7_2
Dietterich, T. (1997). Machine-learning research. AI Magazine, 18(4), 97-136. https://doi.org/10.1609/aimag.v18i4.1324
Dumitrescu, E., Hué, S., Hurlin, C., & Tokpavi, S. (2021). Machine learning for credit scoring: Improving logistic regression with non-linear decision-tree effects. European Journal of Operational Research, 297(3), 1178-1192. https://doi.org/10.1016/j.ejor.2021.06.053
Elizondo, A. (2003). Medición integral del riesgo de crédito. Limusa.
Enterprise.nxt Staff. (2021, 19 de agosto). The rise of artificial intelligence and machine learning. Hewlett Packard Enterprise. https://www.hpe.com/us/en/insights/articles/the-rise-of-artificial-intelligence-and-machine-learning-2108.html
Fritz-Morgenthal, S., Hein, B., & Papenbrock, J. (2022). Financial risk management and explainable, trustworthy, responsible AI. Frontiers in Artificial Intelligence, 5, 1-14. https://doi.org/10.3389/frai.2022.779799
Ghahramani, Z. (2004). Unsupervised learning. En O. Bousquet, U. von Luxburg, y G. Rätsch (Eds.), Advanced lectures on machine learning. Lecture Notes in Computer Science (vol. 3176, pp. 72-112). Springer. https://doi.org/10.1007/978-3-540-28650-9_5
Giacometti, R., Torri, G., Farina, G., & De Giuli, M. (2020). Risk attribution and interconnectedness in the EU via CDS data. Computational Management Science, 17, 549-567. https://doi.org/10.1007/s10287-020-00385-2
Hui Hoo, Z., Candlish, J., & Teare, D. (2017). What is an ROC curve? Emergency Medicine Journal, 34, 357-359. http://dx.doi.org/10.1136/emermed-2017-206735
IBM. (2018, 26 de diciembre). ¿Qué es machine learning? https://www.ibm.com/pe-es/analytics/machine-learning
KPMG Company. (2021, mayo). With asset quality on the brink, supervisors’ focus on credit risk is growing. https://home.kpmg/xx/en/home/insights/2021/05/with-asset-quality-on-the-brink-supervisors-focus-on-credit-risk-is-growing.html
Leo, M., Sharma, S., & Maddulety, K. (2020). Machine learning in banking risk management: A literature review. Risks, 7(1), 1-22. https://doi.org/10.3390/risks7010029
Mashrur, A., Luo, W., Zaidi, N., & Robles-Kelly, A. (2020). Machine learning for financial risk management: A survey. IEEE Access, 8, 203203-203223. https://doi.org/10.1109/ACCESS.2020.3036322
Milojević, N., & Redzepagic, S. (2021). Prospects of artificial intelligence and machine learning application in banking risk management. Journal of Central Banking Theory and Practice, 10(3), 41-57. https://doi.org/10.2478/jcbtp-2021-0023
Moreno, A., Armengol, E., Béjar, J., Belanche, L., Cortés, U., Gavaldà, R., Gimeno, J. M., López, B., Martín, M. & Sánchez, M. (1994). Aprendizaje automático. Edicions UPC.
Nina, H., Pow-Sang, J. A., & Villavicencio, M. (2021). Systematic mapping of the literature on secure software development. IEEE Access, 9, 36852-36867. https://doi.org/10.1109/ACCESS.2021.3062388
Plawiak, P., Abdar, M., Plawiak, J., Makarenkov, V., & Acharya, U. (2020). DGHNL: A new deep genetic hierarchical network of learners for prediction of credit scoring. Information Sciences, 516, 401-418. https://doi.org/10.1016/j.ins.2019.12.045
SAS: Analytics, Artificial Intelligence and Data Management. (2017). Machine learning and artificial intelligence in a brave new world. https://www.sas.com/en_au/insights/articles/analytics/machine-learning-and-artificial-intelligence-in-a-brave-new-world.html
SAS: Analytics, Artificial Intelligence and Data Management. (2015). Credit risk management - What it is and why it matters. Risk Insights. https://www.sas.com/el_gr/insights/risk-management/credit-risk-management.html
Srinivasa Rao, M., Sekhar, C., & Bhattacharyya, D. (2021). Comparative Analysis of Machine Learning Models on Loan Risk Analysis. Advances in Intelligent Systems and Computing, 1280, 81–90. https://doi.org/10.1007/978-981-15-9516-5_7
Superintendencia de Banca, Seguros y AFP. (s. f.). Métodos basados en calificaciones internas. https://www.sbs.gob.pe/Portals/0/jer/pres_doc_basilea/III%20METODO
%20IRB.pdf
Teng, H.-W., & Lee, M. (2020). Estimation procedures of using five alternative machine learning methods for predicting credit card default. En C. Lee, & J. Lee, Handbook of financial econometrics, mathematics, statistics, and machine learning (vol. 4, pp. 3545-3572). https://doi.org/10.1142/9789811202391_0101
Visa, S., Ramsay, B., Ralescu, A., & van der Knaap, E. (2011). Confusion matrix-based feature selection. Proceedings of the 22nd Midwest Artificial Intelligence and Cognitive Science Conference 2011, 120-127.
Zhang, X. D. (2020). A matrix algebra approach to artificial intelligence. Springer.
Zhang, Y., (Ed.). (2010). New Advances in Machine Learning. IntechOpen. https://doi.org/10.5772/225