Real-Time Recognition of Peruvian Sign Language Using Convolutional Neural Networks (CNNs)
Sonia J. León-Jimenez1 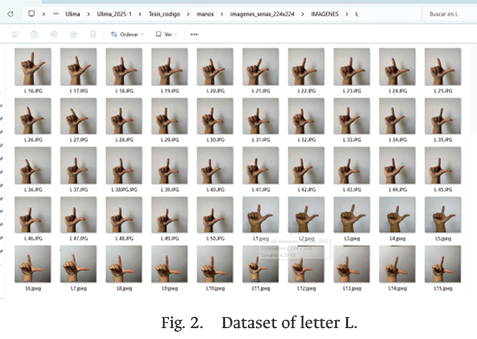 , Claudia León-Chavarri2 , Rafael Chavez-Ugaz3 , Lucia B. Suni-Chavez4 ,
, Claudia León-Chavarri2 , Rafael Chavez-Ugaz3 , Lucia B. Suni-Chavez4 ,
Fabricio H. Paredes-Larroca5 , Ezilda M. Cabrera-Gil6
1([email protected]), 2([email protected]), 3([email protected]), 4([email protected]),
5([email protected]), 6([email protected])
123456 Carrera de Ingeniería Industrial, Universidad de Lima, Perú
Received: 15 August, 2025 / Accepted 5 September, 2025 / Published: 5 June, 2026
https://doi.org/10.26439/ciii2025.8660
Abstract—Inclusive education for people with hearing impairments in many countries still lacks accessible technological tools. This work introduces a prototype for automatic translation of the Peruvian Sign Language (PSL) finger alphabet based on convolutional neural networks (CNNs) combined with support vector machines (SVMs). The system recognizes letters in real time without requiring additional sensors or wearable devices. A proprietary dataset containing up to 50 images per class was used for training under controlled conditions. The prototype achieved an average accuracy of 97%, a word error rate (WER) of 15%, and a response time of 1.8–2.0 s and a processing speed of up to 125 frames per second (fps). These results demonstrate the viability of the system as an inclusive educational tool in both controlled environments and real-life school settings.
Index Terms—Assistive technology, convolutional neural networks (CNNs), inclusive education, Peruvian Sign Language (PSL), sign language recognition.
- Introduction
The inclusion of people with hearing disabilities in the education system continues to be a considerable challenge worldwide, especially in developing countries such as Peru [1]. Despite various institutional efforts, deaf students continue to face persistent barriers, including a shortage of qualified interpreters, limited teacher training in the use of Peruvian Sign Language (PSL), and the low availability of inclusive technological tools [1], [2], [3].
According to the World Health Organization (WHO), approximately 5% of the world’s population—about 430 million people—live with significant hearing loss, a figure that is projected to increase to one in ten people by 2050 [7]. In Peru, children living in poverty are at increased risk of hearing impairment, partly due to untreated middle ear disease and limited access to pediatric ear care, which is associated with worse academic performance [22]. In low- and middle-income countries, people with hearing loss frequently experience restricted access to education, employment and health services, leading to substantial psychosocial burden [8]. Limited access to appropriate language in deaf children can lead to delays in language development, which can cause academic problems and social exclusion. These challenges can also influence emotional development, particularly in contexts where there are communication barriers that restrict interaction with colleagues or educators. [9]. In the long term, the educational barriers can negatively impact the academic outcomes, social participation and inclusion in society. [10].
In response to this problem, deep learning-based technologies, such as CNNs, have demonstrated remarkable effectiveness in visual recognition tasks, including automatic sign interpretation [4], [13], [14]. CNNs are particularly suitable for real-time applications as they enable efficient processing and faster inference compared to traditional computer vision approaches [14], [16]. Recent studies indicate that the integration of CNNs with techniques such as support vector machines enhances classification accuracy for highly similar gestures, thereby increasing their applicability in educational contexts [14], [17].
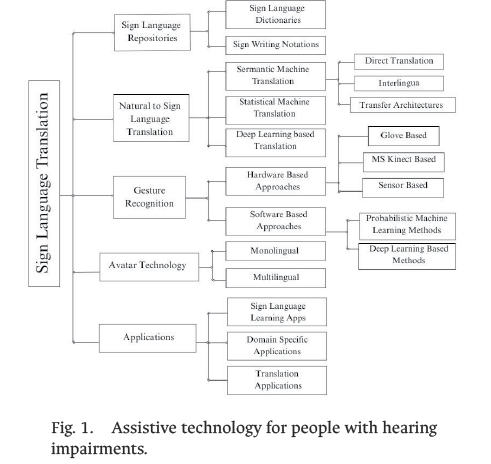
Currently, several prototypes aimed at improving communication for people with hearing disabilities have been proposed, using a variety of technologies, as described and illustrated in Fig. 1. However, many of these approaches exhibit adaptability limitations and rely on wearable devices, such as sensorized gloves, whose accuracy typically ranges from 93.4% to 96% under standard conditions [5], [6]. Although some studies using specialized sensors have achieved accuracies of up to 96% in controlled scenarios [5], [6], these solutions remain intrusive, expensive, and impractical for deployment in conventional classroom environments. In contrast, international studies based on computer vision and CNN models report more consistent accuracies, typically >90% accuracy, in some controlled scenarios above 95% [4], [13], Using polynomial classifiers, recognition accuracy can range from 93.41% to 98.4%, depending on the number of training patterns [25]. These findings indicate that non-invasive and context-aware approaches represent a more viable and relevant alternative, thereby reinforcing the proposed approach of this study.
This project proposes an autonomous, portable, and non-intrusive tool capable of recognizing PSL gestures in real time and automatically translating them into text and voice, without requiring gloves or an internet connection. Using an HD camera and local processing on a computer with an integrated GPU, the proposed system is positioned as an accessible alternative for public educational institutions. Unlike models based on international datasets (ASL, ISL) [11], [17], this prototype will be trained using data specific to the Peruvian context, thereby increasing its relevance and accuracy in national scenarios. It is expected to achieve an average accuracy in the range of 95% to 99%, a word error rate (WER) of approximately 15%, and a response time of no more than 2.5 s, so that the tool can effectively contribute to the educational inclusion of people with hearing disabilities through a scalable, accessible, and adaptable solution to the Peruvian school system.
A. Prototypes Based on Virtual Dictionaries and Educational Platforms
One of the most relevant developments in the national context is the PSL (PUCP) Virtual Bilingual Dictionary, which enables the translation of approximately 750 words from Spanish into sign language through manual on-screen selection [2]. Another example is Yapaykuy, a mobile application that converts speech to text and text to speech, with plans to incorporate predefined gesture recognition [3]. These initiatives have favored basic access to sign language; however, their operation remains static and does not support real-time visual recognition. Furthermore, these solutions rely on limited databases and do not facilitate natural interaction in dynamic educational contexts, reflecting the gaps that still exist in inclusive education in Peru [1], as well as the international challenges reported in terms of accessibility and educational outcomes for people with hearing disabilities [7]–[10].
- Comparative technical attributes are summarized as follows:
- Input: Manual selection; no automatic visual recognition [2] [3].
- Output: Text and speech; gestural fluidity is not considered [2].
- Limitation: They depend on closed databases without real-time scalability [1] [7].
B. Prototypes Based on Physical Devices (Gloves, Sensors and Wearables)
At the international level, some developments have used physical devices such as sensorized gloves to capture hand movements. Promising recognition performance in controlled settings has been approached by wereable instrumented gloves and inertial sensors; however, they require calibration and may reduce the comfort and portability in an educational environment. Although these solutions have achieved accuracies of 96.3% in segmented samples and 91.2% in real time—and in some cases up to 96% when using specialized sensors— [5], [6], they present limitations in terms of cost, user comfort, and the need for constant calibration. Furthermore, several studies have indicated that deaf people prefer non-intrusive technologies that respect their natural body language [12]. In this sense, although technically effective, gloves interfere with natural gestures and are impractical for prolonged use in educational environments.
- Comparative technical attributes are summarized as follows:
- Accuracy: >90%, but dependent on calibration, hardware used and constant maintenance [5] [6].
- Cost: high because it requires specialized hardware [5] [6].
- Limitation: They interfere with natural gestures and reduce comfort in a classroom [12].
C. Prototypes Based on Visual Recognition With Machine Learning
The latest systems use deep learning models, such as CNNs, trained on gesture images. Examples include SignNet and BranTNet—the latter based on transfer learning—which have been designed for sign languages such as ASL or ISL, using high-quality standardized datasets [4], [11], [13], [14]. These models have reported accuracies ranging from 93% to 98% under controlled conditions [4], [13], , [25]. However, these models typically require large volumes of data, connectivity to external servers, and training in cultural contexts different from that of Peru. Furthermore, in many cases, they focus exclusively on isolated letters or words, without considering sentence-level structure or the particularities of the PSL [11], [17].
Comparative technical attributes are summarized as follows:
- Accuracy: above 90%under controlled conditions [4], [13], [25].
- Requirements: large volumes of data and connectivity with external servers [11], [17].
- Limitation: trained in international contexts, without considering particularities of the PSL [11], [17].
- Methodology
Quality Function Deployment (QFD) was used as a comparative analysis tool, allowing the attributes that the proposed prototype must address to be evaluated against existing solutions. To this end, the main user requirements were reviewed: clear and accessible visualization, real-time gesture recognition, portability and ergonomics, simultaneous audio and video feedback, and adaptation to the PSL. Each requirement was assigned a weighting based on its relevance, and the performance of the proposed prototype was compared with that of several international patents [19], [20], [21].
The results show that the proposed system achieved the maximum score across all criteria, achieving 97% accuracy, operating in real time at 125 fps, working with a standard, low-cost, non-intrusive camera, offering immediate visual and auditory feedback, and being trained on a proprietary PSL dataset, thereby ensuring cultural relevance. The dataset was generated under controlled but variable conditions, using a 1080p webcam to capture the 28 letters of the PSL, including “Ñ”, with at least 50 images per class. Data acquisition sessions were conducted on different days, introducing variations in lighting, distance, and hand orientation to better simulate real-world environments. Gesture references were obtained through direct visual observation in a Peruvian Sign Language (PSL) school and were subsequently replicated during data collection, ensuring that the captured samples reflected the authentic characteristics of the local context. In contrast, the reviewed patents, while reporting accuracies above 90%, rely on gloves or other specialized devices, provide partial feedback, and focus on foreign sign languages, thereby limiting their ergonomics, accessibility, and applicability to the Peruvian context.
The proposed modular system for PSL translation consists of various phases that integrate computer vision and deep learning techniques. The main performance indicators targeted were: achieving an accuracy between 95% and 99 %, ensuring real-time operation with a minimum speed of 120 fps, maintaining a response time of less than 2 s, obtaining a WER of no more than 15% in dynamic sequences, and ensuring system non-intrusiveness through the use of a low-cost, standard camera adapted to the PSL context.
The experimentation phases followed a validation protocol widely used in computer vision [13], [14], consisting of dividing the dataset into 80% for training and 20% for testing, ensuring the evaluation of the model with data not seen during learning. In contrast, previous studies based on LSTM architectures have evaluated performance using sequence-based metrics such as BLEU, ROUGE, and CIDEr [15]. In real-time experiments, the system response rate in frames per second (fps) was also measured, and a five-frame moving average was applied to smooth predictions, thus stabilizing the output and reducing instantaneous classification fluctuations, improving output stability and reducing instantaneous classification fluctuations.
The experimental process was progressively designed in three phases, using 5, 15 and 50 images per class. This strategy enabled the evaluation of the impact of dataset size on the model’s generalization capability. The deep learning literature indicates that small datasets tend to induce overfitting, which limits the system’s ability to recognize new variations in the samples [13], [14]. In the first phase, using only five images per class, the model exhibited low accuracy and high classification instability. In the second phase, with 15 images per class, a substantial improvement in prediction stability was observed, reflecting increased diversity in the training samples. Finally, in the third phase, using 50 images per class, the system achieved its best performance, attaining a competitive level of accuracy consistent with that reported in international CNN-based sign recognition studies, where accuracies exceed 90% on larger datasets [4].
A. Data Collection and Use of Formulas
A proprietary dataset was constructed from video captures acquired with a high-resolution webcam (1080p at 30 fps), focusing exclusively on the user’s hands against a neutral background. For each of the 28 letters of the PSL alphabet, including “Ñ”, a minimum of 50 images per class were captured, as shown in Fig. 2. Sessions were conducted on different days, with intentional variations in lighting, distance, and orientation to ensure diversity and improve model generalization, as recommended in [13].
For letters involving movement, such as “J”, “Ñ”, and “Z”, video sequences were recorded and segmented into individual frames at a rate of 5–10 fps, following a strategy similar to that used in DeepASLR [14] and in the hybrid architectures described in [17], as illustrated in Fig. 3.
B. Preprocessing
The preprocessing pipeline consisted of several stages, including conversion to grayscale to reduce computational complexity, resizing to 64x64 pixels to standardize the input of the models, and normalization of pixel values in a range between 0 and 1. Additionally, data augmentation techniques were applied, such as random rotation, translation, horizontal mirroring, and brightness modification, with the aim of increasing system robustness to real-world environmental variations. This strategy follows the approach suggested in [23] for LSTM-based models trained with augmented data. The corresponding Python code is as follows:
def preprocesar_frame(frame):
roi=frame[ROI_TOP_LEFT[1]:ROI_BOTTOM_RIGHT[1],ROI_TOP_LEFT[0]:ROI_BOTTOM_RIGHT[0]]
resized=cv2.resize(roi,(IMG_WIDTH,IMG_HEIGHT))
normalized = resized / 255.0
return np.expand_dims(normalized, axis=0), roi
C. Model Architecture
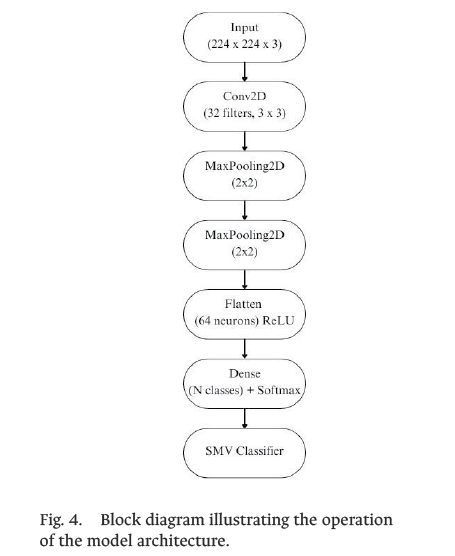
The basic architecture for static sign recognition consisted of a CNN with three convolutional layers, intermediate pooling layers, ReLU activation functions, and a final fully connected layer with SoftMax for multiclass classification as illustrated in Fig. 4. To improve accuracy for gestures with a high degree of similarity (e.g., “M” and “N”), a SVM classifier was integrated as a post-feature extraction stage, functioning as a refined decision layer, as proposed in [14].
In parallel, CNN-LSTM architecture was implemented for dynamic letters. This model receives a sequence of images (consecutive frames of the same gesture) as input and learns to capture temporal progression through recurrent layers. This approach is supported by works such as [17].
D. Real-Time Integration and Execution
The system was implemented in Python using libraries such as OpenCV for video capture, TensorFlow/Keras for model training and deployment, and Pyttsx3 for text-to-speech synthesis. During execution, the camera continuously detects the region of interest (ROI) corresponding to the user’s hands and processes each frame in real time. The model predicts the corresponding class and accumulates the recognized letters, as illustrated in Fig. 5. A temporal segmentation algorithm based on pauses between gestures enables the differentiation of individual letters, words, or complete phrases. The resulting text is displayed on the screen using a simple graphical interface and can be automatically converted into speech, facilitating immediate communication between the user and their environment, as shown in Fig. 6.
E. Testing, Validation and Metrics
From a statistical perspective, the validity of the performance metrics is directly influenced by the size of the test sample. With the current configuration of 50 images per class (28 letters, for a total of 1400 images) and an 80/20 training–testing split, the test set comprised approximately 280 samples. This number allows estimating the overall accuracy with a confidence interval close to ± 6–7% at 95% confidence, which is acceptable for an experimental prototype. However, the literature suggests that reducing the margin of error to ± 5% requires at least 384 test samples [13], [14] Likewise, for per-class metrics such as precision or recall, it it is recommended to have a sufficient number of validation samples per category to ensure the statistical reliability of per-class metrics such as precision and recall. With 50 images per class, the system obtains, on average, about ten test samples per letter, which limits the statistical stability of these metrics. Therefore, as future work, it is proposed to expand the dataset to 100–150 images per class or to apply stratified k-fold cross-validation in order to increase the reliability of results.
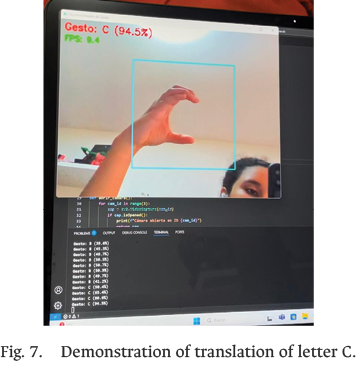
The prototype was also subjected to alpha and beta testing with volunteer users to evaluate performance under both controlled conditions and real-world environments. Accuracy, sensitivity, and the confusion matrix were used for static models, while for dynamic letters, the WER was used together with sequence-level precision and recall, following the guidelines proposed in DeepASLR [14]. Response time was measured by directly timing the interval between image acquisition and prediction output, to determine an average processing speed of 125 fps, which confirms the system’s real-time viability, as shown in Fig. 7.
- Results
The prototype developed for the automatic translation of the PSL finger alphabet achieved an overall accuracy of 97% using a dataset of 50 images per class, together with a WER of 15% and an average response time of 1.8–2.0 s with a processing speed of 125 frames per second, thereby confirming its viability for real-time operation. Tests were conducted under controlled laboratory conditions, with stable lighting (300 lumens/250 lux), a uniform background, and minimal visual interference, thereby ensuring that the observed variations were attributable to the model’s performance rather than to external factors.
The class-wise analysis showed that letters with distinctive features (L, T, and Y) achieved accuracies above 95%, whereas morphologically similar pairs (M/N and U/V) exhibited higher misclassification rates. These results demonstrate that the proposed system is competitive with international reference models and represents a non-invasive, low-cost alternative tailored to the Peruvian context, with strong potential for deployment in inclusive educational settings.
However, the statistical reliability at the class level was limited by the number of available samples (approximately ten test images per letter). Therefore, future work includes expanding the dataset to 100–150 images per class, incorporating additional metrics such as recall and F1-score, validating the system in real educational scenarios with end users, and evaluating its performance under more variable lighting conditions to ensure robustness in uncontrolled contexts. The use of five images per class was intended to represent a minimal scenario for observing overfitting and classification instability under limited data conditions, whereas the configuration with 15 images per class provided a mid-level setting that increased sample variability and improved prediction stability. Finally, using 50 images per class provided a more representative dataset, enabling the system to achieve competitive accuracy levels consistent with those reported in the literature for CNN-based sign recognition [13]–[15]. The corresponding test results are summarized in Table I, whereas the performance curve is shown in Fig. 8.
A. Tests With Five Images per Class
In an initial exploratory phase, the model was trained using five images per class of the finger alphabet. The results showed high instability in predictions, especially for visually similar letters. Overall accuracy was low, and the system exhibited limited generalization to slight variations in posture, lighting, and background.
B. Tests With 15 Images per Class
In the second iteration, the dataset was increased to 15 images per class. This expansion resulted in substantial improvements in model learning, with a significant increase in overall accuracy and reduced sensitivity to external conditions. However, some misclassifications persisted among classes with similar morphologies.
C. Tests With 50 Images per Class
In the third phase, the model was trained using 50 images per class. Under this configuration, the system achieved its best overall performance. High recognition accuracy, a decreased error rate, and a more stable response were observed under controlled lighting conditions (300 lumens/250 lux). Furthermore, the average processing speed remained at 125 fps.
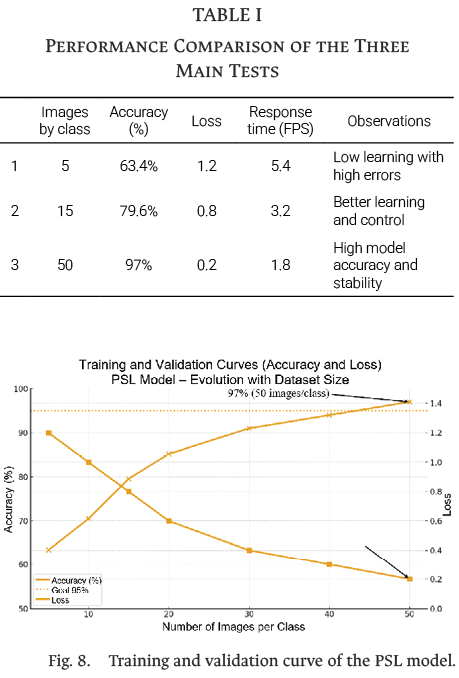
Performance varied slightly depending on the letter. The most difficult classes to identify were those with similar handforms, such as “M” and “N,” or “U” and “V,” which exhibited higher error rates. In contrast, letters with distinctive features such as “L,” “T,” or “Y” achieved accuracies above 95%.
Under the configuration with 50 images per class, the model achieved accuracies above 90% for 21 of the 26 evaluated letters and maintained a minimum accuracy of 85% for the remaining classes, demonstrating strong generalization capability under optimal environmental conditions.
In addition to overall accuracy, other relevant metrics were calculated to further assess the system’s overall performance:
- WER: 15% with 50 images/class
- Average accuracy of 97%
- Average processing speed: 125 fps
These metrics confirm that the system is functional in real time and suitable for educational environments provided that controlled conditions—such as a uniform background, stable lighting, and minimal visual interference—are maintained.
- Discussion
The results obtained from the experimental tests enable a comparison of the system’s performance with respect to the proposed objectives and existing technological solutions. The initial objective of this prototype was to achieve an accuracy between 95% and 99% in recognizing letters of the PSL finger alphabet while maintaining a real-time response time of less than 2 s, thereby allowing the system to be considered viable for inclusive educational settings.
Despite the promising results, this project presents several limitations. In particular, the dataset size was limited to 50 images per class, which restricts the statistical reliability of per-class performance metrics. All experiments were conducted under controlled conditions of lighting and background conditions, which limits the system’s robustness in real-world environments. In addition, the prototype focused primarily on static letters of the PSL alphabet and a limited set of dynamic gestures, without addressing the recognition of complete words or sentences. Finally, validation with end users in real classroom settings has not yet been conducted, which is necessary to assess usability and scalability.
A. Comparison With Accessibility Mobile Applications
National platforms such as [2] and [3] provide basic accessibility features through manual selection or voice-to-text conversion. However, both are limited to static, predefined vocabularies without visual gesture recognition. In contrast, the proposed prototype achieved an average accuracy of 97% in real-time operation at 125 fps, providing automatic visual-to-speech translation of live gestures and overcoming the static nature and limited scalability of these applications.
B. Comparison With Systems Based on Physical Sensors
Wearable-device–based systems, such as those reported in [5] and [6], achieve accuracy ranges under standard conditions and up to 96% when specialized sensors are used. Although technically effective, these solutions are intrusive, costly, and require frequent calibration, which makes them impractical for routine classroom use. In contrast, the proposed model relies solely on a standard camera and achieves a real-time correct prediction rate of 91.3% using 50 images per class, thus eliminating the discomfort and cost associated with gloves and sensors.
C. Comparison With International CNN Recognition Models
International proposals such as [4], [13], and [15] reported accuracies in the range of 93–98% using large ASL or ISL datasets under controlled conditions. Similarly, advanced hybrid models such as those presented in [11], [14], [16], and [17] demonstrate robust performance; however, they typically depend on large-scale datasets, cloud-based infrastructure, and application contexts different from Peru. By contrast, the proposed prototype achieved an accuracy of 97% and a WER of 15% using a locally constructed Peruvian dataset, thereby ensuring cultural relevance while operating on low-cost hardware.
D. Comparison With Patented Solutions
Patented devices such as those described in [19]–[21] focus on glove-based or camera-assisted translation of foreign sign languages and report accuracies above 90%. However, these solutions rely on specialized hardware and do not address the specific requirements of the Peruvian context. This prototype differs by integrating CNN and SVM models trained on a PSL dataset, providing a scalable, camera-only solution tailored to local conditions.
- Conclusions
In summary, the prototype meets the established objectives by exceeding 95% accuracy, achieving an average accuracy of 97%, and operating in real time at a processing speed of 125 frames per second. This performance is competitive with international models and offers a practical advantage over intrusive solutions such as sensor-enhanced gloves. Furthermore, the objective of developing a non-invasive and low-cost solution was achieved, with an approximate 30% savings compared to sensor-based systems. Its contextualization within the Peruvian environment was guaranteed by using the Bilingual Dictionary of PSL as a reference.
Its accessible and educational nature reinforces its potential as an inclusive tool. However, it is acknowledged that the results are based on tests under controlled conditions and with a dataset limited to 50 images per class. Therefore, future work will focus on validating the system in real-life classroom settings, using a larger sample size and incorporating additional evaluation metrics such as recall and F1 score.
References
[1] Ombudsman’s Office, “Situation of inclusive education in Peru,” Ombudsman’s Office, Lima, Peru, 2022.
[2] Pontificia Universidad Católica del Perú, “Diccionario LSP al Español [Virtual Bilingual Dictionary of Peruvian Sign Language],” 2022. [Online]. Available: https://diccionariolsp.pucp.edu.pe/search-by-text
[3] Yapaykuy. (2023). App Store. Lima, Peru. [Mobile app]. Available: https://apps.apple.com/pe/app/yapaykuy/id6478118708
[4] K. Abbas, R. Kumar, and P. Jain, “Sign language recognition using CNN,” IEEE Trans. Neural Netw. Learn. Syst., vol. 32, no. 5, pp. 1941–1953, May 2021.
[5] J. DelPreto, J. Hughes, M. D’Aria, M. de Fazio, and D. Rus, “A wearable smart glove and its application of pose and gesture detection to sign language classification,” IEEE Robot. Autom. Lett., vol. 7, no. 4, pp. 10589–10596, 2022, doi: 10.1109/LRA.2022.3191232.
[6] A. Ji, Y. Wang, X. Miao, T. Fan, B. Ru, L. Liu, R. Nie, and S. Qiu, “Dataglove for sign language recognition of people with hearing and speech impairment via wearable inertial sensors,” Sensors, vol. 23, no. 15, Art. no. 6693, 2023, doi: 10.3390/s23156693
[7] A. Radzi, S. Salim, M. H. Abd Wahab, M. M. Abdul Jamil, and T. C. Phing, “Development of a wearable sensor glove for real-time sign language translation". Ann. Emerg. Technol. Comput., vol. 7, no. 5, pp. 25–38. doi: 10.33166/AETiC.2023.05.003
[8] World Health Organization, World Report on Hearing. Geneva, Switzerland: WHO, 2021. [Online]. Available: https://www.who.int/publications/i/item/world-report-on-hearing
[9] H. Knoors, and M. Marschark, “Language planning for the 21st century: Revisiting bilingual language policy for deaf children,” J. Deaf Stud. Deaf Educ., vol. 17, no. 3, pp. 291–305, 2012, doi: 10.1093/deafed/ens018.
[10] C. Tannenbaum-Baruchi, B. Ahad Ha’am, and R. Harari, “Accessibility and support in higher education: A case study of deaf and hard of hearing students’ perceptions,” High. Educ., 2025, doi: 10.1007/s10734-025-01586-x.
[11] H. Wang, et al., “Enhanced open biomass burning detection: The BranTNet approach using UAV aerial imagery and deep learning for environmental protection and health preservation,” Ecol. Indic., vol. 154, Art. no. 110788, 2023, doi: 10.1016/j.ecolind.2023.110788.
[12] L. Findlater et al., “Design preferences and barriers for deaf and hard of hearing users of mobile technology,” in Proc. ASSETS 2019, Pittsburgh, PA, USA, Oct. 28–30 2019.
[13] A. Gangal, A. Kuppahally, and M. Ravindran, Sign Language Recognition with Convolutional Neural Networks, Stanford CS231n Project Report, 2024. [Online]. Available: https://cs231n.stanford.edu/2024/papers/sign-language-recognition-with-convolutional-neural-networks.pdf
[14] A. Kasapbaşı, A. E. A. Elbushra, O. Al-Hardanee, and A. Yilmaz, “DeepASLR: A CNN-based human–computer interface for American Sign Language recognition for hearing-impaired individuals,” Comput. Methods Programs Biomed. Update, vol. 2, p. 100048, Jan. 2022, doi: 10.1016/j.cmpbup.2021.100048.
[15] S. Subburaj, S. Murugavalli, and B. Muthusenthil, “Sign language video to text conversion via optimised LSTM with improved motion estimation,” J. Exp. Theor. Artif. Intell., vol. 37, no. 1, pp. 163-182, 2024, doi: 10.1080/0952813X.2024.2380991.
[16] Y. Wang, H. Jiang, Y. Sun, and L. Xu, “A static sign language recognition method enhanced with self-attention mechanisms,” Sensors, vol. 24, no. 21, p. 6921, 2024, doi: 10.3390/s24216921.
[17] A. Elhagry and R. G. Elrayes, “Egyptian Sign Language recognition using CNN and LSTM,” arXiv, Jul. 28, 2021. [Online]. Available: https://arxiv.org/abs/2107.13647
[18] S. M. S. Swetha, M. S. Muneshwara, V. Venkatesh, S. M. S. Kudremane, R. S. Nair, and V. H. Vismitha, “Developing a translation model to bridge ASL and Indian regional languages using neural networks,” in Proc. 2025 Int. Conf. Comput. Sustain. Intell. Future (COMP-SIF), Bangalore, India, Mar. 21–22, 2025, pp. 1–6.
[19] Indian Patent Office, A sign language translator glove, Patent application IN201841026260 A, Jul. 20, 2018. [Online]. Available: https://patentscope.wipo.int/search/es/detail.jsf?docId=IN224134191&_cid=P20-MFKLFW-88048-1
[20] Indian Patent Office, Sign language translator for deaf and speech impaired, Patent application IN202321041213 A, 2023. [Online]. Available: https://patentscope.wipo.int/search/es/detail.jsf?docId=IN414860224&_cid=P20-MFKLGX-89227-1
[21] Korean Intellectual Property Office, Sign language translator and method thereof, particularly for translating the video of a finger language into a voice or text, Patent KR1020100026701 A, 2010. [Online]. Available: https://patentscope.wipo.int/search/es/detail.jsf?docId=KR5842487&_cid=P20-MFKLHM-90082-1
[22] J. A. Czechowicz et al., “Hearing impairment and poverty: The epidemiology of ear disease in Peruvian schoolchildren,” Otolaryngol. Head Neck Surg., vol. 142, no. 2, pp. 272–277, 2010. doi: 10.1016/j.otohns.2009.10.040
[23] B. Alsharif, A. S. Altaher, A. Altaher, M. Liyas, and E. Alalwany, “Deep learning technology to recognize American Sign Language alphabet,” Sensors, vol. 23, no. 19, p. 7970, 2023. doi: 10.3390/s23197970
[24] D. Kothadiya, C. Bhatt, K. Sapariya, K. Patel, A.-B. Gil-González, and J. M. Corchado, “Deepsign: Sign language detection and recognition using deep learning,” Electronics, vol. 11, no. 11, p. 1780, 2022. doi: 10.3390/electronics11111780
[25] K. Assaleh and M. Al-Rousan, “Recognition of Arabic sign language alphabet using polynomial classifiers,” EURASIP Journal on Advances in Signal Processing, vol. 2005, Art. no. 507614, 2005, doi: 10.1155/ASP.2005.2136